本篇文章給大家帶來了關于python的相關知識,其中主要介紹了關于線程的創建與常用的方法,還有一些線程演示案例,下面一起來看一下,希望對大家有幫助。

推薦學習:python視頻教程
線程的創建與使用
在Python中有很多的多線程模塊,其中 threading 模塊就是比較常用的。下面就來看一下如何利用 threading 創建線程以及它的常用方法。
線程的創建 -threading
函數名 介紹 舉例 Thread 創建線程 Thread(target, args) Thread 的動能介紹:通過調用
threading模塊的Thread類來實例化一個線程對象;它有兩個參數:target 與 args(與創建進程時,參數相同)。target為創建線程時要執行的函數,而args為是要執行這個函數時需要傳入的參數。
線程對象的常用方法
接下里看一下線程對象中都有哪些常用的方法:
函數名 介紹 用法 start 啟動線程 start() join 阻塞線程直到線程執行結束 join(timeout=None) getName 獲取線程的名字 getName() setName 設置線程的名字 setName(name) is_alive 判斷線程是否存活 is_alive() setDaemon 守護線程 setDaemon(True)
- start 函數:啟動一個線程;沒有任何返回值和參數。
- join 函數:和進程中的 join 函數一樣;阻塞當前的程序,主線程的任務需要等待當前子線程的任務結束后才可以繼續執行;參數為
timeout:代表阻塞的超時時間。- getName 函數:獲取當前線程的名字。
- setName 函數:給當前的線程設置名字;參數為
name:是一個字符串類型- is_alive 函數:判斷當前線程的狀態是否存貨
- setDaemon 函數:它是一個守護線程;如果腳本任務執行完成之后,即便進程池還沒有執行完成業務也會被強行終止。子線程也是如此,如果希望主進程或者是主線程先執行完自己的業務之后,依然允許子線程繼續工作而不是強行關閉它們,只需要設置
setDaemon()為True就可以了。PS:通過上面的介紹,會發現其實線程對象里面的函數幾乎和進程對象中的函數非常相似,它們的使用方法和使用場景幾乎是相同的。
線程演示案例
單線程初始案例
演示 多線程之前 先看一下下面這個案例,運行結束后看看共計耗時多久
1、定義一個列表,里面寫一些內容。
2、再定義一個新列表,將上一個列表的內容隨機寫入到新列表中;并且刪除上一個列表中隨機獲取到的內容。
3、這里需要使用到
r andom內置模塊
代碼示例如下:
# coding:utf-8import timeimport random old_lists = ['羅馬假日', '怦然心動', '時空戀旅人', '天使愛美麗', '天使之城', '倒霉愛神', '愛樂之城']new_lists = []def work(): if len(old_lists) == 0: # 判斷 old_list 的長度,如果為0 ,則表示 該列表的內容已經被刪光了 return ''old_list' 列表內容已經全部刪除' old_choice_data = random.choice(old_lists) # random 模塊的 choice函數可以隨機獲取傳入的 old_list 的元素 old_lists.remove(old_choice_data) # 當獲取到這個隨機元素之后,將該元素從 old_lists 中刪除 new_choice_data = '%s_new' % old_choice_data # 將隨機獲取到的隨機元素通過格式化方式重新賦值,區別于之前的元素 new_lists.append(new_choice_data) # 將格式化的新的隨機元素添加至 new_lists 列表 time.sleep(1)if __name__ == '__main__': strat_time = time.time() for i in range(len(old_lists)): work() if len(old_lists) ==0: print(''old_lists' 當前為:{}'.format(None)) else: print((''old_lists' 當前為:{}'.format(old_lists))) if not len(new_lists) == 0: print((''new_lists' 當前為:{}'.format(new_lists))) else: print(''new_lists' 當前為:{}'.format(None)) end_time = time.time() print('運行結束,累計耗時:{} 秒'.format(end_time - strat_time))
運行結果如下:
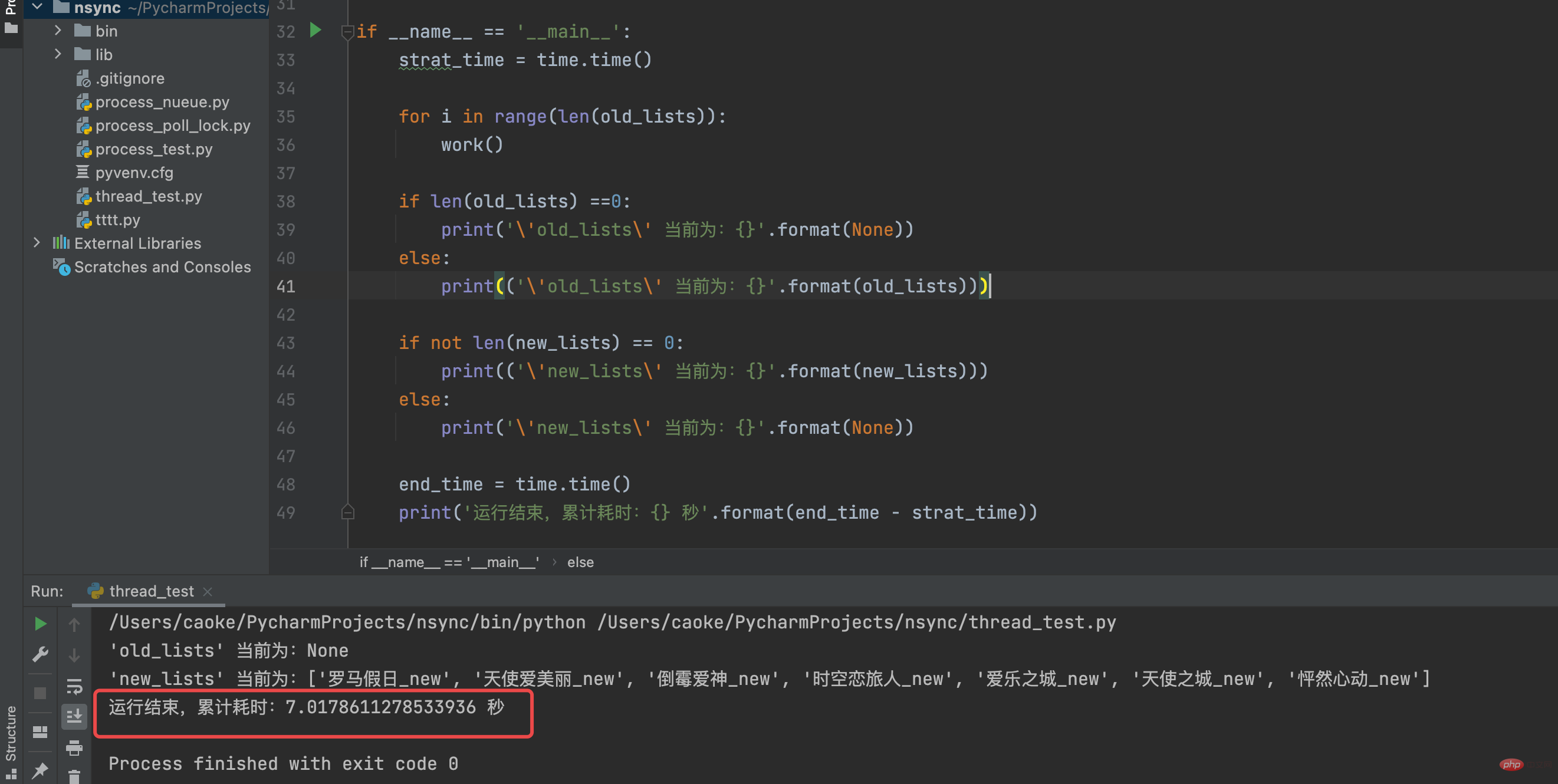
從運行輸出結果我們可以看到整個腳本運行共計耗時7秒,而且 new_lists 列表內的元素都經過格式化處理后加上了 _new ;不僅如此, 因為 random模塊的choice函數 原因,new_lists 的內容順序與 old_lists 也是不一樣;每次運行順序都會不一樣,所以 old_lists 的順序是無法得到保障的。
多線程演示案例
代碼示例如下:
# coding:utf-8import timeimport randomimport threading old_lists = ['羅馬假日', '怦然心動', '時空戀旅人', '天使愛美麗', '天使之城', '倒霉愛神', '愛樂之城']new_lists = []def work(): if len(old_lists) == 0: # 判斷 old_list 的長度,如果為0 ,則表示 該列表的內容已經被刪光了 return ''old_list' 列表內容已經全部刪除' old_choice_data = random.choice(old_lists) # random 模塊的 choice函數可以隨機獲取傳入的 old_list 的元素 old_lists.remove(old_choice_data) # 當獲取到這個隨機元素之后,將該元素從 old_lists 中刪除 new_choice_data = '%s_new' % old_choice_data # 將隨機獲取到的隨機元素通過格式化方式重新賦值,區別于之前的元素 new_lists.append(new_choice_data) # 將格式化的新的隨機元素添加至 new_lists 列表 time.sleep(1)if __name__ == '__main__': strat_time = time.time() print(''old_lists'初始長度為:{}'.format(len(old_lists))) # 獲取 old_lists 與 new_lists 最初始的長度 print(''new_lists'初始長度為:{}'.format(len(new_lists))) thread_list = [] # 定義一個空的 thread_list 對象,用以下方添加每個線程 for i in range(len(old_lists)): thread_work = threading.Thread(target=work) # 定義一個線程實例化對象執行 work 函數,因為 work 函數沒有參數所以不用傳 args thread_list.append(thread_work) # 將 thread_work 添加進 thread_list thread_work.start() # 啟動每一個線程 for t in thread_list: # 通過for循環將每一個線程進行阻塞 t.join() if len(old_lists) ==0: print(''old_lists' 當前為:{}'.format(None), '當前長度為:{}'.format(len(old_lists))) else: print((''old_lists' 當前為:{}'.format(old_lists))) if not len(new_lists) == 0: print(''new_lists' 當前長度為:{}'.format(len(new_lists))) print(''new_lists' 當前的值為:{}'.format(new_lists)) else: print(''new_lists' 當前為:{}'.format(None)) end_time = time.time() print('運行結束,累計耗時:{} 秒'.format(end_time - strat_time))
運行結果如下:
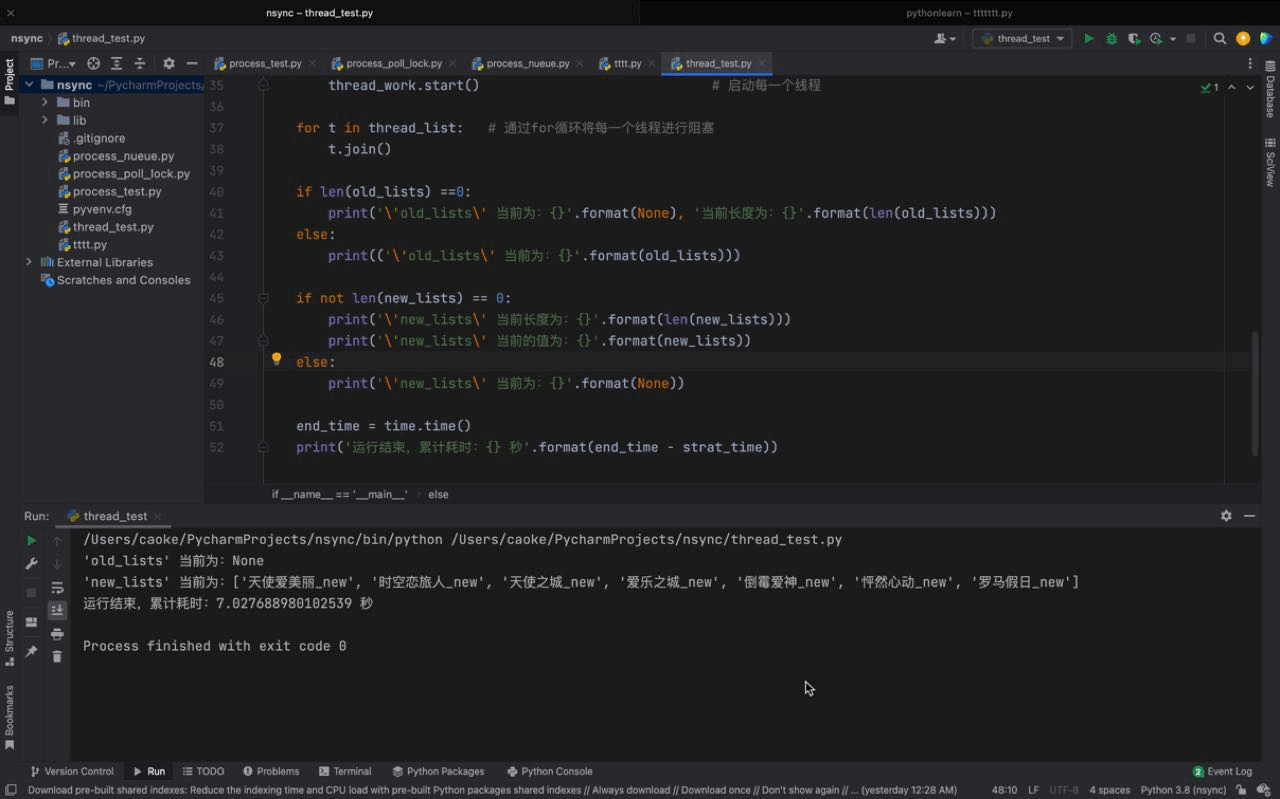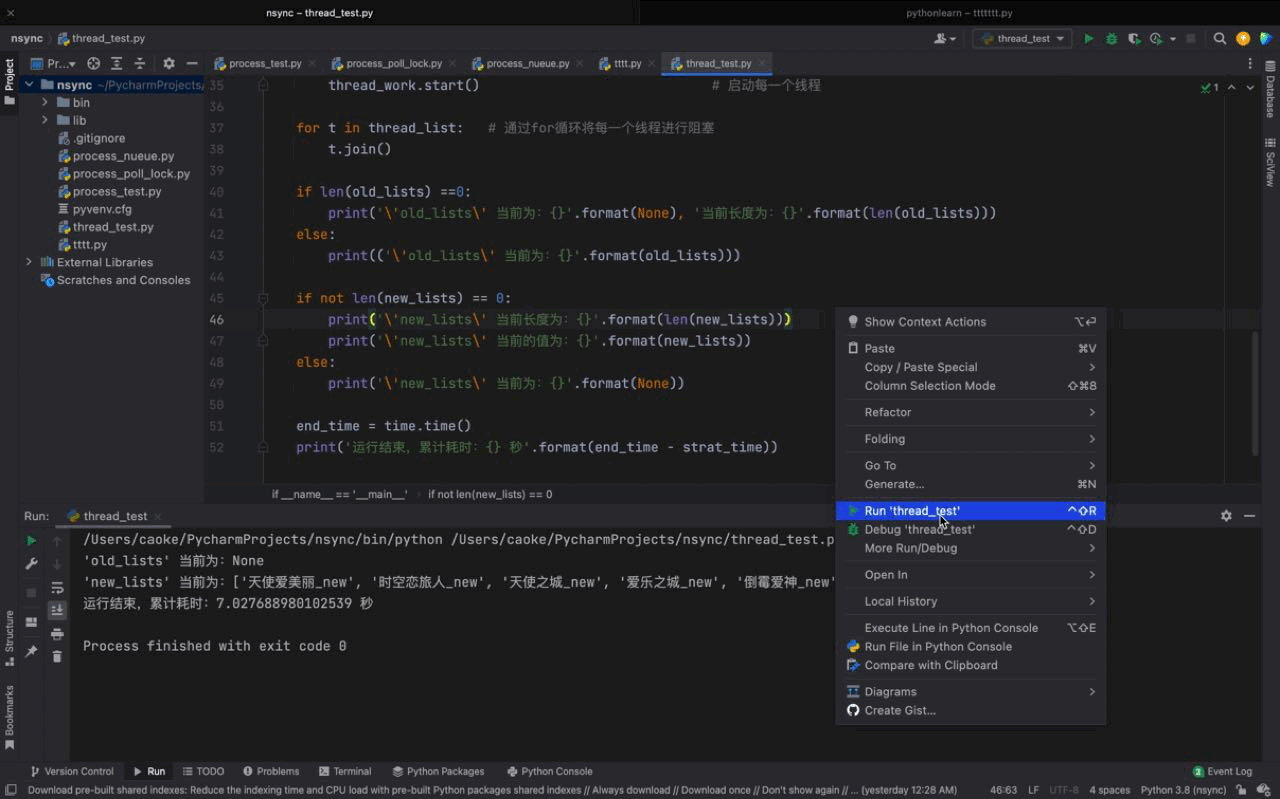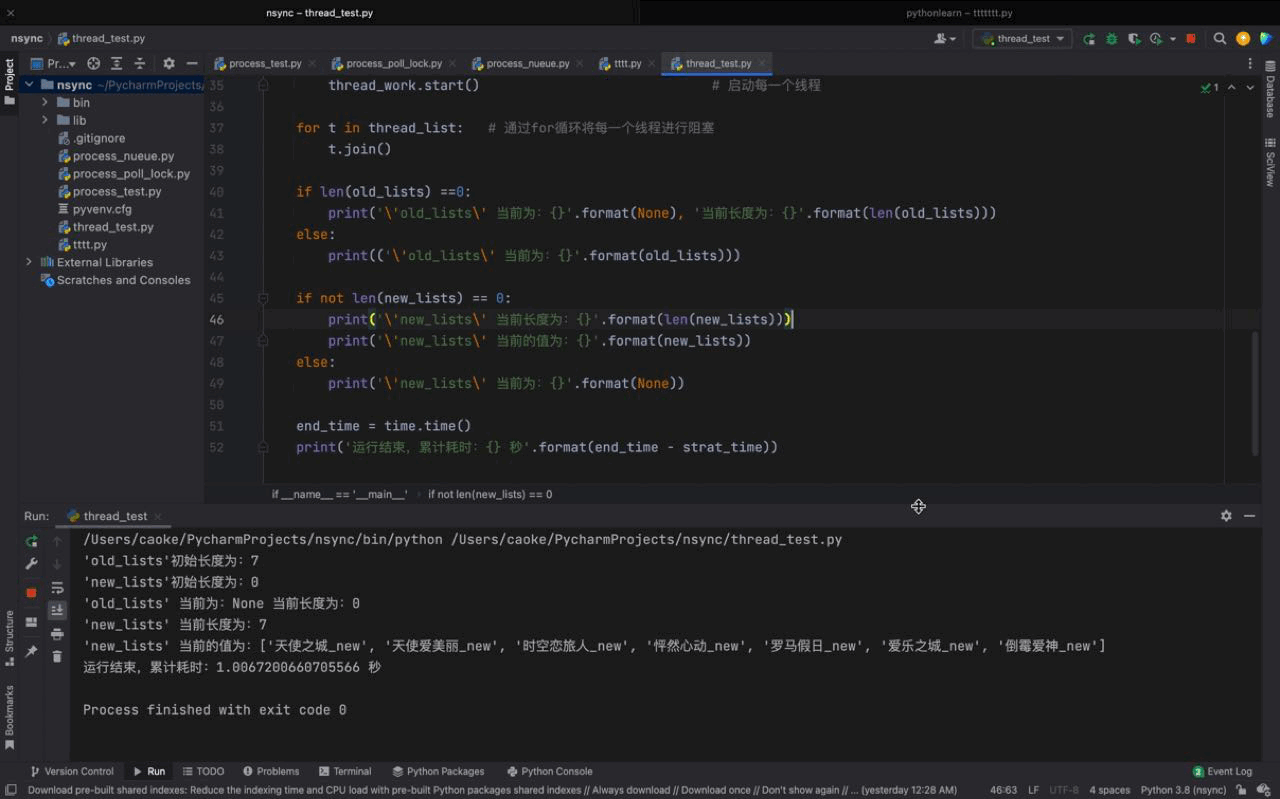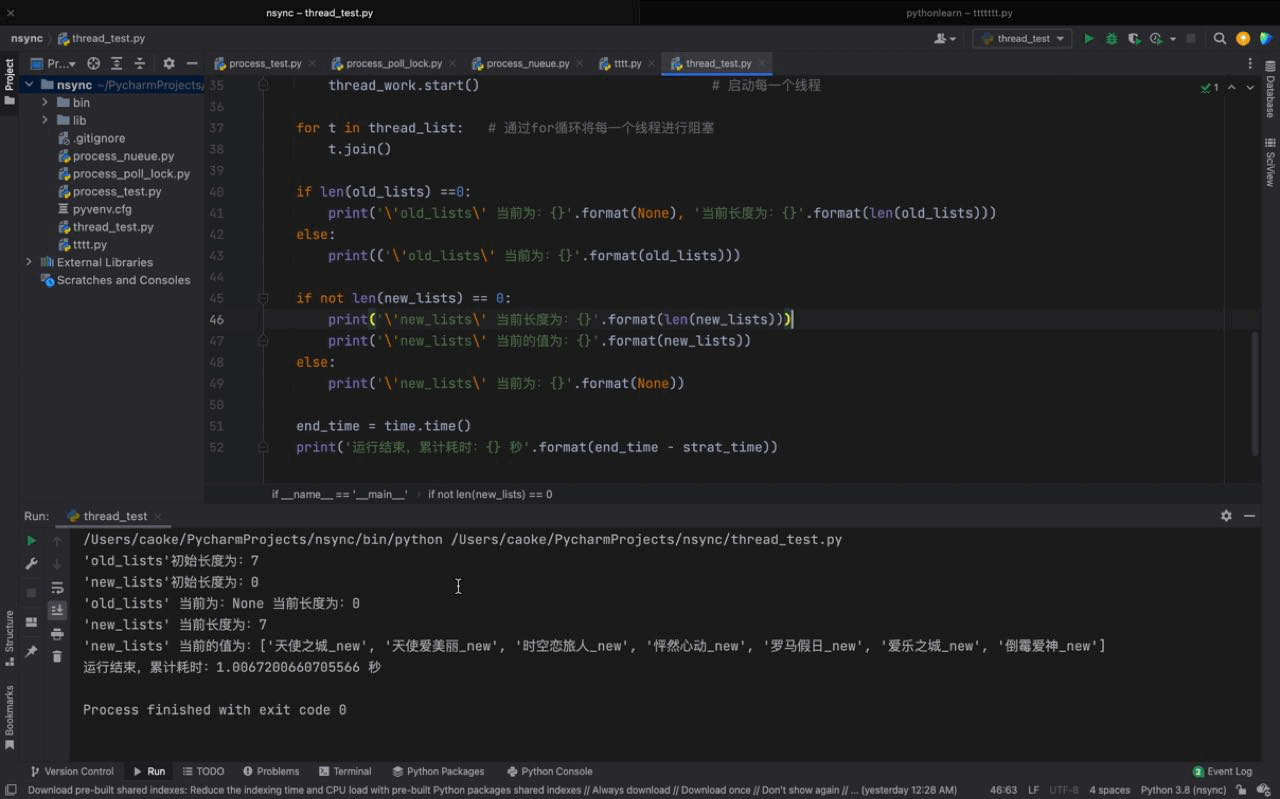
從運行的結果來看,我們初始的單線程任務耗時為 7秒,在使用多線程之后,僅耗時 1秒就完成了,大大的提高了我們的運行效率。
線程的問題
通過上面的練習,我們發現線程的使用方法幾乎與進程是一模一樣的。它們都可以互不干擾的執行程序,也可以使得主線程的程序不需要等待子線程的任務完成之后再去執行。只不過剛剛的演示案例中我們使用了 join() 函數進行了阻塞,這里可以吧 join() 去掉,看看執行效果。
與進程一樣,線程也存在著一定的問題。
- 線程執行的函數,也同樣是無法獲取返回值的。
- 當多個線程同時修改文件一樣會造成被修改文件的數據錯亂的錯誤(因為都是并發去操作一個文件,特別是在處理交易場景的時候,需要尤為注意)。
關于這些線程中存在的問題同樣是可以解決的,在下一章節的 線程池與全局鎖 我們會有詳細的介紹。
推薦學習:python視頻教程
